
不会写代码如何进行大数据文本分析——短语抽取篇
- 2020-03-31
- admin
上一期栏目中我们介绍了如何利用锐研·云文析进行词频统计并最终生成词云图。(《不会写代码如何进行大数据文本分析——词频统计篇》)事实上,除了简单的词频统计,云文析还能更进一步进行短语统计(支持N-GRAM分析算法),词组数可选择两到四词不等。
N-Gram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列。常应用于搜索引擎或输入法的猜想或者提示,在这里只是借助该算法实现简单的短语抽取以便更好的对文本内容进行描述性分析。

还是以疫情期间收集到的1733条第一财经官网新闻数据为例,我们选择了内容字段进行短语抽取,具体步骤如下:
首先在数据库分析中新建短语抽取,我们在这里选择了两词抽取、三词抽取和四词抽取以作对比示范,大家可以根据具体需求进行调整。
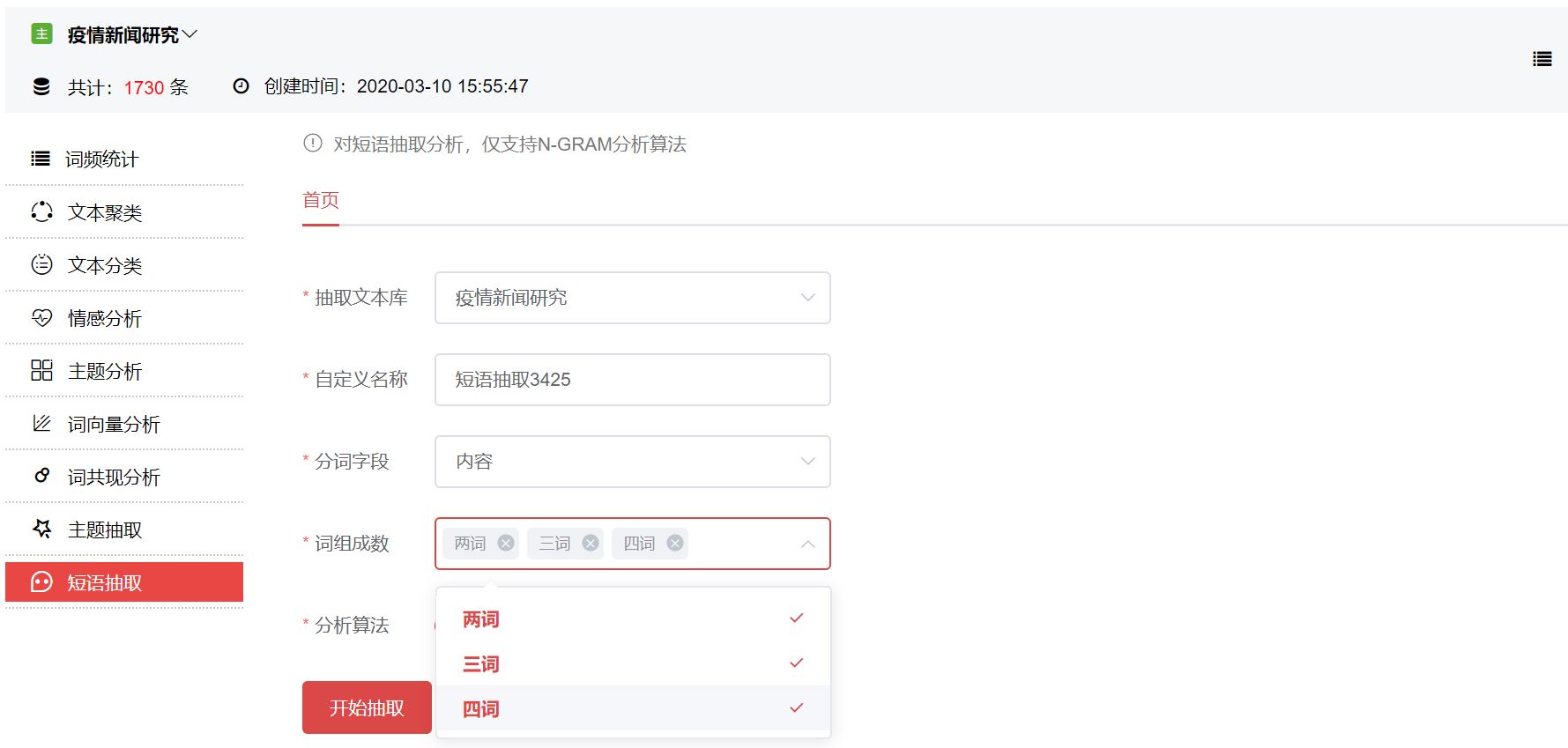
系统显示运行成功后,点击右边箭头查看抽取结果
全部抽取结果如下,点击词组筛选可以分别查看两词、三词、四词抽取结果
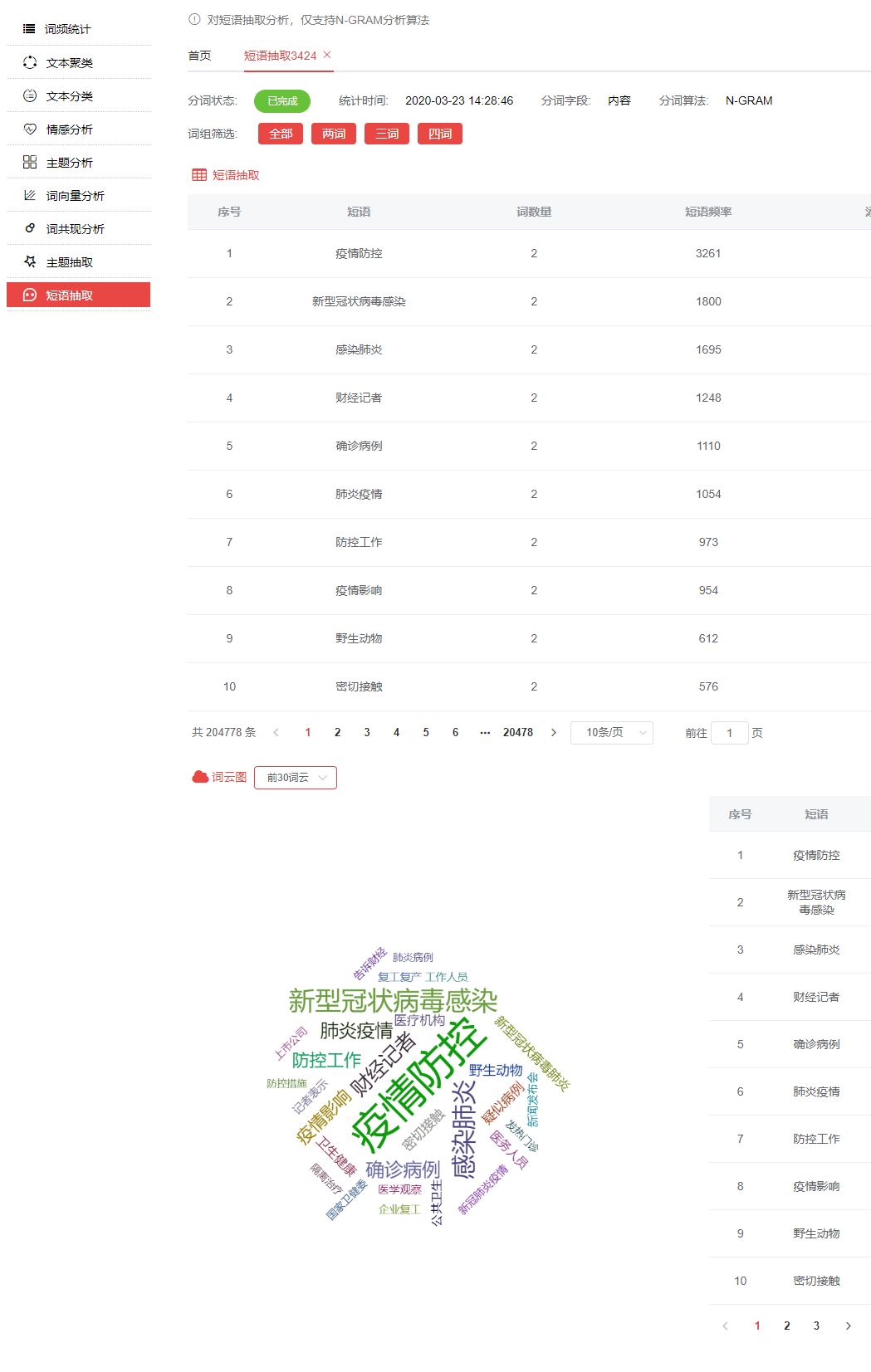
在这里,我们先选择查看两词抽取结果,由于选择的文本内容来源媒体报道,不免有一些固定格式及记者称呼对结果产生干扰,我们选择删除了排序第4的词语【财经记者】和排序第17的【记者表示】。

最后,选择生成前30词云图,两词短语抽取最终结果如下图(字体越大,代表出现频率越高): 三三词短语抽取结果如下图:
三三词短语抽取结果如下图:
 锐研云文析作为文本大数据分析与挖掘云平台,可应用自然语言处理、机器学习、人工智能等技术对大规模文本数据进行分析挖掘,并呈现可视化分析结果。今后,锐研团队会分享更多数据分析相关实用工具及案例,希望此文能为您提供一些帮助。
锐研云文析作为文本大数据分析与挖掘云平台,可应用自然语言处理、机器学习、人工智能等技术对大规模文本数据进行分析挖掘,并呈现可视化分析结果。今后,锐研团队会分享更多数据分析相关实用工具及案例,希望此文能为您提供一些帮助。

发表评论
新闻动态
