
不会写代码如何进行大数据分析——文本分类篇
- 2020-04-10
- admin
一、传统文本分类
文本分类是常见的自然语言处理,指按照一定的分类体系或规则对文本实现自动划归类别的过程。社会科学领域中常应用于信息索引、数字图书管理、情报过滤等;商业领域中则常应用于分析社交媒体中的大众情感、将新闻文章按主题分类等。
传统的文本分类主要依靠人工完成,费时费力;基于大数据文本挖掘的文本分类则具备专业门槛,一般包括文本预处理、分词、模型构建和分类几个过程,社会科学领域的同仁们在各自的专业领域中是佼佼者,在复杂的机器语言面前却是门外汉。
如何摆脱传统文本分类的复杂繁琐,提高文本分类的效率、降低成本,同时又能找到更便捷的辅助工具完成专业程序员才能实现的任务?
二、锐研·云文析-文本分类
锐研·云文析的文本分类功能基于机器学习分类训练集进行,无须复杂代码即可实现文本分类。由于文本内容差异,云文析平台在提供系统已有分类训练集的同时,设置了自定义分类训练集,用户可根据自身需要建立不同的分类训练集以供机器学习,最终实现大批量数据的处理。
依然以疫情期间我们爬取到的第一财经相关新闻为例,本期文章将示范如何对这批数据进行文本分类:

我们想对近千条新闻文本进行报道主题的分类,首先就需要人工设定文本分类标准供机器学习,我们参考了人大RUC工作坊在《2286篇肺炎报道观察:谁在新闻里发声?》一文中对新闻报道主题的分类标准,以及考虑到此次疫情仍在进展中、财经类媒体的报道方向,我们将新闻报道主题分为以下十类:
防控措施、数据通报、疫情现状及前线动态、科普/科研进展、对日常生活影响、对行业影响、其他、典型人物事件、企业社会担当、慈善志愿活动。
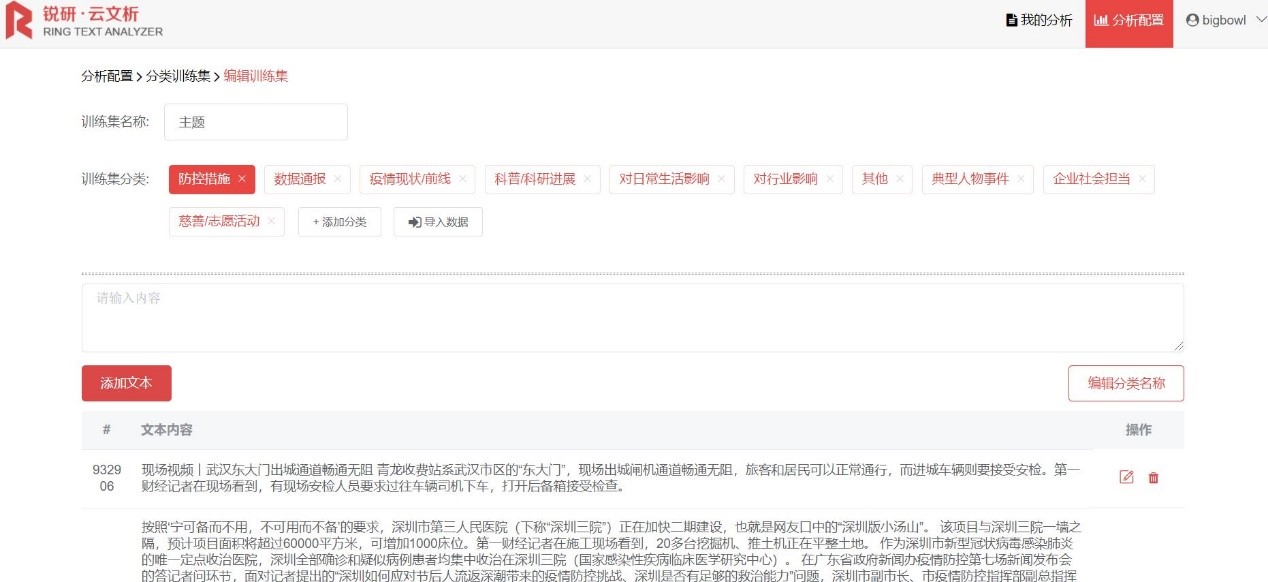
此次疫情数据共1733条,我们抽取了其中的200条对内容字段进行人工判断,将文本内容按照上述十个类别,分别添加至各类别下供机器参考学习。添加方式有两种,可以手动录入文本内容,也可选择【导入数据】按钮导入excel文件,如下图所示新建【主题】训练集,不同类别可录入多项文本内容。
Step 1 建立分类训练集
STEP 2 进行文本分类
建立好分类训练集后,我们就可以对文本进行分类。选择新建文本分类,分类字段选择【内容】字段,训练集选择刚才建立的【主题】分类训练集
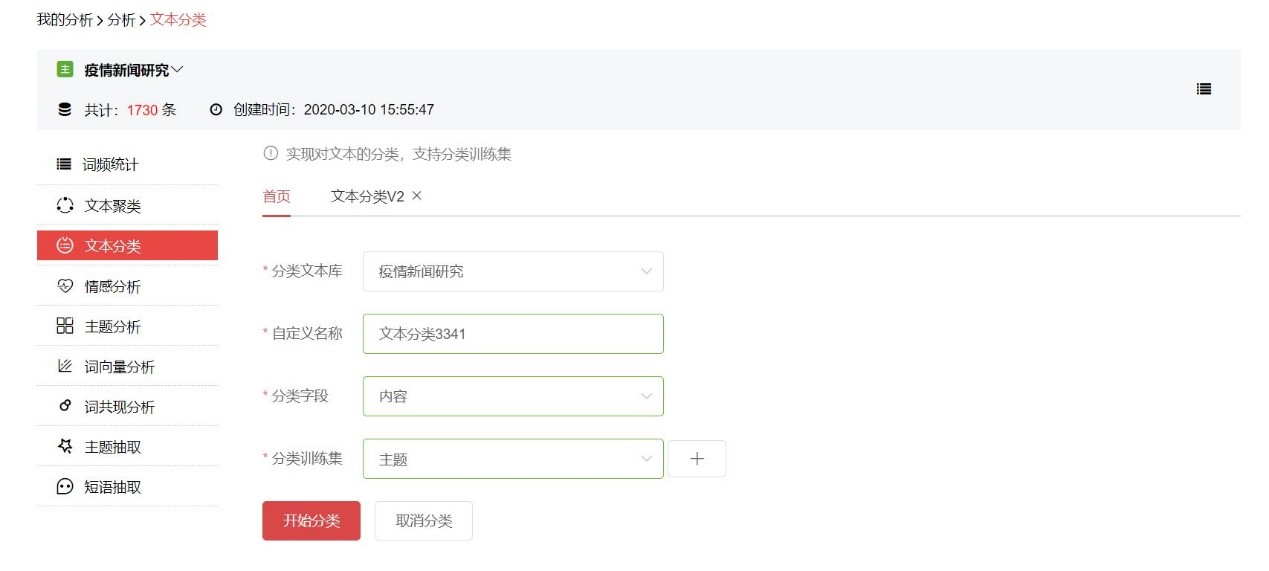
分类运行成功后,点击图标查看分类结果
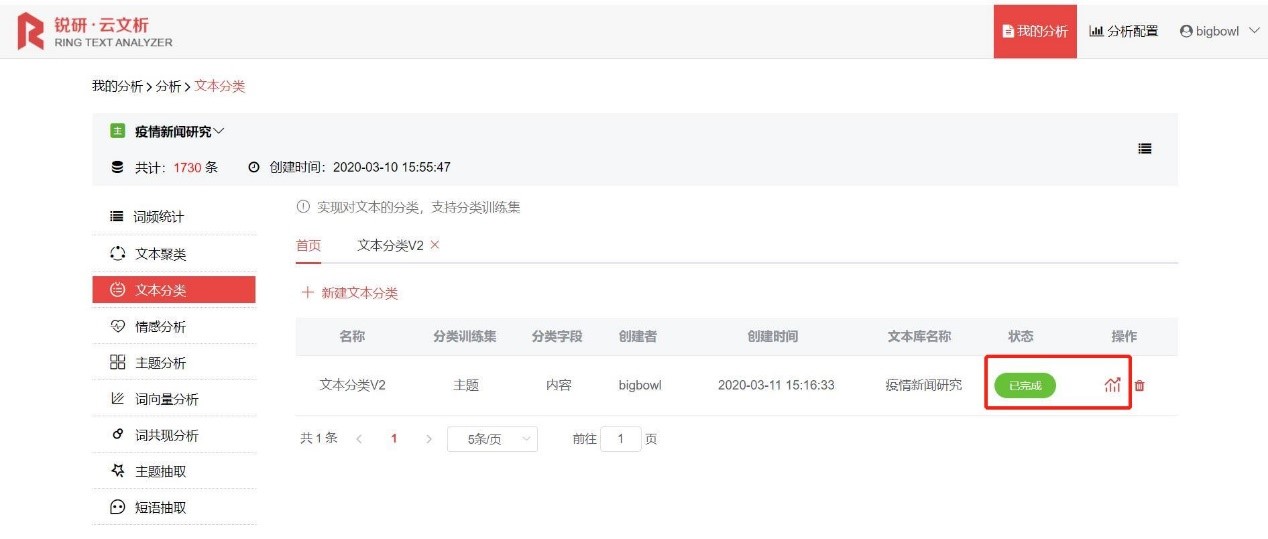
文本分类结果如下,点击柱状图和饼状图可查看具体占比;点击【分析结果展示】可查看不同类别下的文章内容、文章在该分类的概率等。
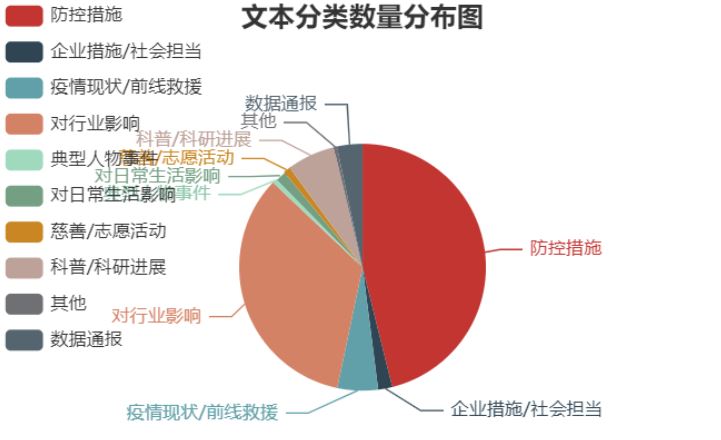
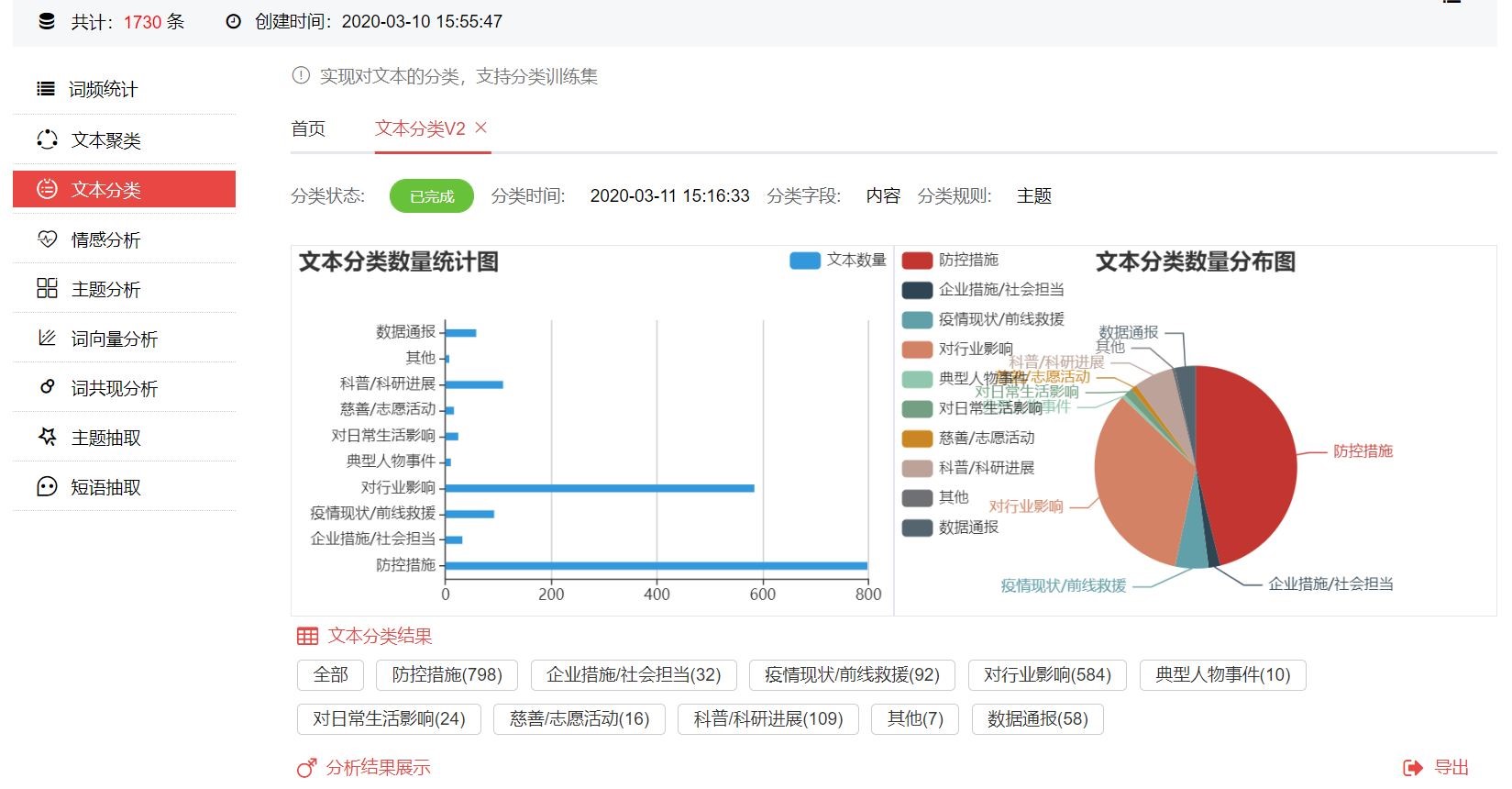 可以看出,第一财经疫情相关报道中,关于防控措施主题的报道占比最多,共798篇,占比46.13%,由于疫情仍在进展中,防控措施仍在不断进行,相关报道数量最多较为合理;紧随其后的是对行业影响主题的报道,共584篇,占比33.76%;而科普/科研进展、疫情现状相关报道分别位列第三第四,占比分别是6.3%和5.32%。
可以看出,第一财经疫情相关报道中,关于防控措施主题的报道占比最多,共798篇,占比46.13%,由于疫情仍在进展中,防控措施仍在不断进行,相关报道数量最多较为合理;紧随其后的是对行业影响主题的报道,共584篇,占比33.76%;而科普/科研进展、疫情现状相关报道分别位列第三第四,占比分别是6.3%和5.32%。
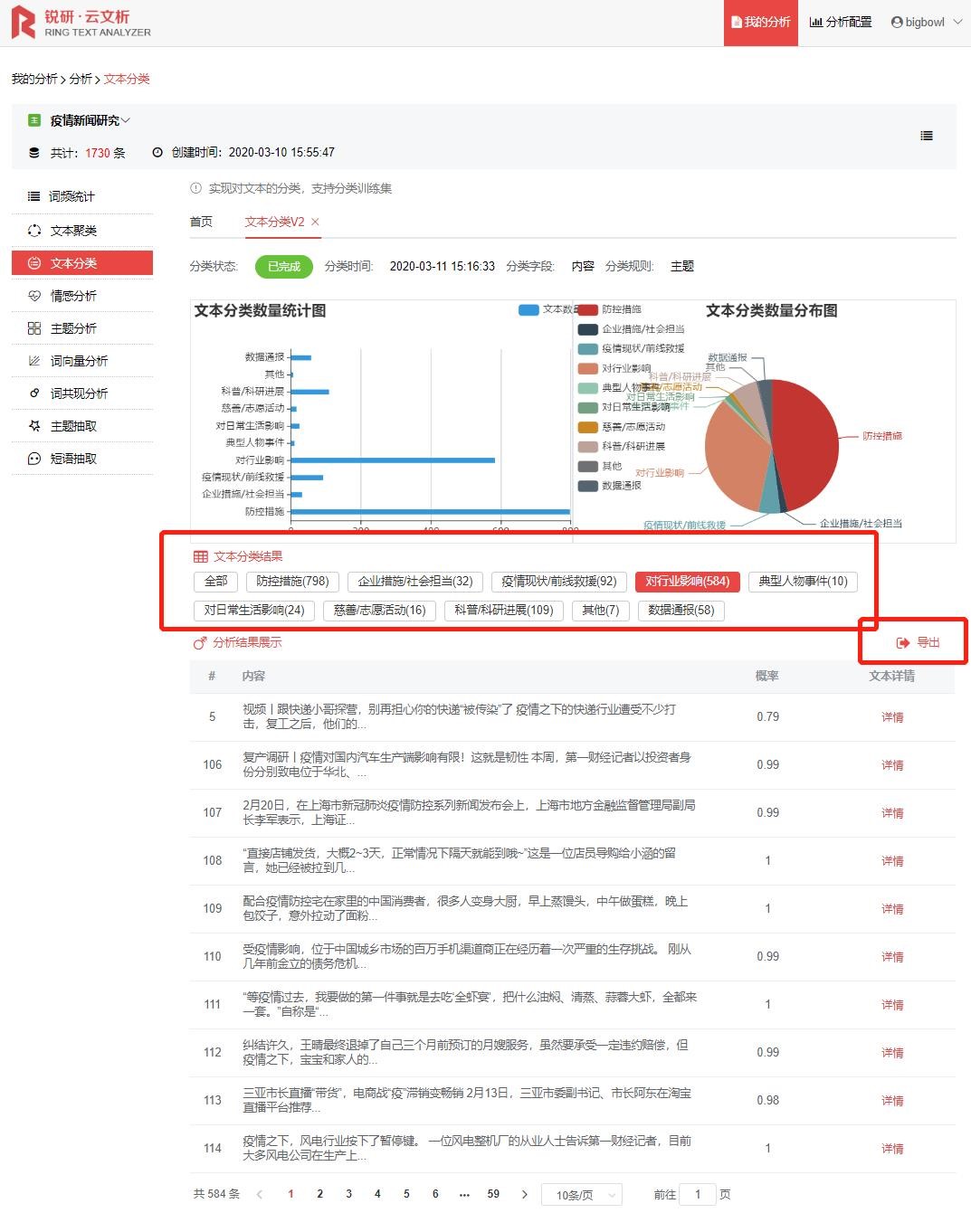
文本分类后,想要进一步研究不同类别下的文章主题,我们可以文本分类结果中选择自己需要的类别,进行二次分析(目前锐研·云文析文本分类结果支持以excel格式导出数据),再重新建立文本库导入数据进行主题分析。例如,第一财经作为财经类细分领域专业媒体,在此次疫情中着重报道了哪些行业,疫情对该行业的冲击力如何?我们就可以抽取分类结果中【对行业影响】大类,导出数据后再导入云文析,进行主题分析。(详情可见——不会写代码如何进行大数据文本分析——主题分析篇)
需要注意的是,文本分类结果的有效性取决于前期分类训练集的准确性,在自定义分类训练集时需要人工对文本进行准确预判,后期机器学习才能在人工基础上为您进行精准的批量文本数据处理。
锐研·云文析作为文本大数据分析与挖掘云平台,可应用自然语言处理、机器学习、人工智能等技术对大规模文本数据进行分析挖掘,并呈现可视化分析结果。今后,锐研团队会分享更多社会科学研究相关实用工具及案例,希望此文能为您提供一些帮助。

